
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- SRE
- 리트코드
- 제노블레이드 2
- 네이버 검색 시스템
- 프로그래머스
- baekjoon
- git
- 격리수준
- ASF-110
- 알고리즘 종류 정리
- 코딩테스트
- algorithm
- 백트래킹
- C++
- programmers
- 프로콘 갈림현상
- 취준
- Pro-Con
- Python
- python3
- GitHub Desktop
- DP
- Github
- 자소서
- 백준
- Ultimate Search
- 프로콘
- LeetCode
- 알고리즘
- Algorithmus
- Today
- Total
산타는 없다
데이터베이스 B/B+ tree 인덱스 구조 본문
데이터베이스 인덱스 자료구조로 B-tree를 사용합니다.
균형 트리 중 B-tree를 사용하는 이유는 B-tree는 하나의 노드에 여러 개의 데이터 요소를 저장할 수 있는 점과 데이터 탐색뿐 아니라 저장, 수정, 삭제에도 항상 O(logN)의 시간 복잡도를 가지기 때문이라고 생각됩니다.
또 항상 정렬된 상태를 유지하고 있고 참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다는 장점도 가지고 있습니다.
B Tree 인덱스 특징
B Tree 인덱스는 다음과 같은 특징을 가지고 있습니다. (차수가 n일 경우)
- 루트 블록은 리프 블록이 아닌 이상 적어도 두 개의 서브 트리를 갖는다.
- 루트 블록과 리프 블록을 제외한 각 블록은 최소 n/2개의 포인터를 갖고 적어도 n/2-1개의 키 값을 갖는다.
- 모든 리프 노드는 같은 수준(레벨, 깊이)에 있다.
- 한 노드 안에 있는 키 값은 오름차순을 유지한다.
B Tree 인덱스 구조
B-Tree 인덱스는 루트 블록, 브랜치 블록, 리브 블록으로 이루어져 있습니다.
- 루트 블록 (Root Block) : 브랜치 블록의 가장 최상위 노드
- 브랜치 블록 (Branch Block) : 분기를 위한 목적으로 사용되며 브랜치 블록은 다음 단계를 가리키는 포인터를 가지고 있다.
- 리프 블록 (Leaf Block) : 인덱스를 구성하는 컬럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드 식별자(RID, Record Indentifier/Rowid)로 구성되어 있다. 인덱스는 인덱스를 구성하는 컬럼의 값으로 정렬되어 있다.
[B+ tree 한정 : 양방향 링크를 가지고 있어 오름차순, 내림차순으로 검색이 가능합니다]
인덱스 자료구조로 B 트리 뿐만 아니라 B+트리도 쓰이는데 어떤 트리를 사용하는지에 따라 트리의 새부적인 구조가 달라지게 됩니다. B트리는 myISAM 스토리지 엔진에서 사용하고 B+ 트리는 InnoDB 스토리지 엔진에서 사용합니다.
루트 블록과 브랜치 블록은 [Key : DBA(하위 노드의 Data Block Address)] 구조로 되어있습니다.
여기서 B 트리와 B+ 트리의 차이점이 나타나게 되는데 B트리는 Key가 실제로 저장되어 있는 레코드 포인터를 가지고 있지만 B+트리는 레코드 포인터를 리프 블록에서만 가지고 있고 브랜치 블록에서는 Key값만 저장하고 레코드 포인터는 가지고 있지 않습니다. 또, 브랜치 블록에서 저장된 Key 값은 하위 노드의 범위를 뜻하게 됩니다.
Key값을 기준으로 좌우의 하위 노드를 가리키는 포인터를 가지고 있어 그림으로 표현한다면

이렇게 표현할 수 있고 주황색 영역은 하위노드를 가리키는 포인터를 가지고 있게 됩니다.
key1 왼쪽에 있는 포인터는 key1보다 작은 데이터를 저장하는 하위노드를 가리키고 오른쪽의 포인터는 key1과 key2 사이의 데이터를 저장하는 하위노드를 가리키게 됩니다.
그리고 블럭이 가지고 있는 포인터의 갯수를 저장하고 있습니다.
리프 블록은 [Key : RID] 구조로 되어있습니다. 이때 B+트리는 이전과 다음 리프노드를 가리키는 포인터도 가지고 있어 순차탐색을 가능하게 합니다. 즉, 오름차순, 내림차순 검색이 가능합니다.
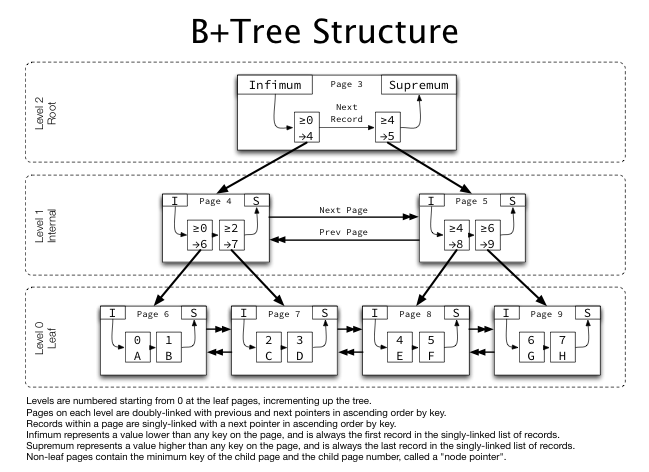
B트리와 B+트리의 차이점을 정리해 보겠습니다.
B Tree
- 모든 노드에서 Key값과 RID를 저장하고 있다.
- 검색 범위가 여러 블록이 해당 된다면 해당 블록을 탐색 후 다시 상위 브랜치 노드를 거쳐서 탐색하게된다. (중위 순회)
- 자주 탐색하는 값이 리프 블록에 있지않고 루트 블록에 가까이 있다면 탐색 속도가 B+Tree에 비해 빠를 가능성이 있다.
B+Tree
- 리프 노드에서만 Key값과 RID를 저장하고 있다
- 범위 검색 시 리프 블록까지 내려가야 하지만 이후 탐색은 링크드리스트로 탐색이 가능해 B Tree에 비해 빠르다.
- 검색 시 무조건 리프 블록까지 내려가야 해서 특정 값을 탐색 시 B Tree에 비해 느릴 가능성이 있다.
마지막으로 B Tree 탐색 과정을 정리해 보겠습니다.
- 루트 블록에서 부터 시작해서 해당하는 값을 탐색한다.
- 찾고자 하는 값이 작으면 왼쪽 포인터 크면 오른쪽 포인터로 이동한다.(B+트리일 경우 크거나 같으면 오른쪽)
- B 트리일 경우 일치하는 값을 찾을 때까지 하위 블록을 탐색하며 B+트리는 해당 리프 노드가 있을 리프 블록까지 탐색하고 리프 블록까지 내려와 값를 찾을 탐색한다.
'Computer Science > 데이터베이스' 카테고리의 다른 글
| [MySql] SQL select Query 실행 순서 (0) | 2021.07.14 |
|---|---|
| 데이터베이스의 인덱스 알고리즘 (0) | 2021.05.14 |
| MySql의 스토리지 엔진 비교 (0) | 2021.05.13 |
| MySql의 인덱스 자료구조 (0) | 2021.05.13 |
| 트랜잭션(Transaction) 격리 수준(Isolation Level) (0) | 2021.04.27 |